Start with the screenshot, not the slogan.
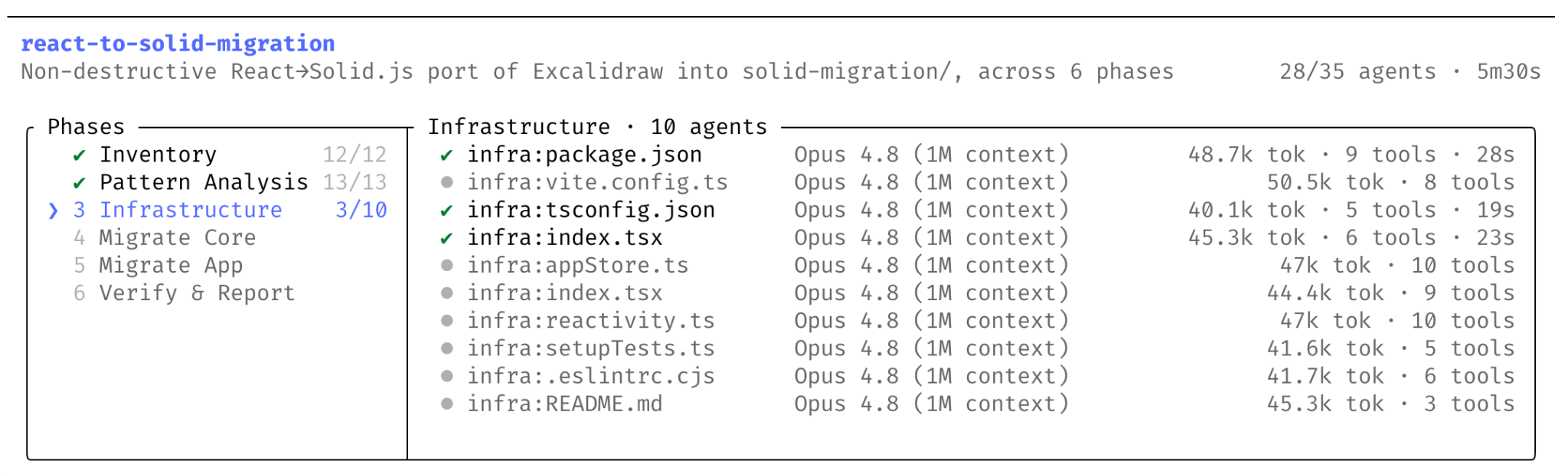
The important thing in this Claude Code update is not that an AI can write more code. It is that Claude can now build a temporary operating system for a complex task: plan it, split it into smaller jobs, send those jobs to separate agents, verify the outputs, and return a coordinated result.
That matters for physicians because the same control pattern is starting to appear in clinical AI: one model drafts, another checks sources, another looks for safety risks, and a human reviewer makes the final call. Dynamic workflows are not a clinical tool by themselves. They are a useful window into how serious AI review systems are being designed.
Clinician Summary
- What changed: Claude Code can create and run dynamic workflows: JavaScript orchestration scripts that coordinate many subagents in one session.
- Why it matters: The workflow can separate work into independent context windows, which helps with long, parallel, verification-heavy tasks.
- Where the danger sits: More agents do not automatically mean more truth. Poor prompts, weak source rules, or missing human review can multiply errors faster.
- Clinical translation: The useful pattern is not “let the AI decide.” It is “make every claim, source, privacy boundary, and safety assumption visible before a clinician signs off.”
What Anthropic Actually Announced
On May 28, 2026, Anthropic announced dynamic workflows in Claude Code. The company described them as a research-preview feature for tasks that are too large or too adversarial for a single pass: codebase-wide bug hunts, large migrations, and work that needs independent verification before the result reaches the user.
The workflow starts when you ask Claude to create one, or when you use the Claude Code ultracode effort setting. The official docs describe /effort ultracode as combining extra-high reasoning with automatic workflow orchestration, and /workflows as the progress view for watching, pausing, resuming, or saving workflows.
The screenshot above is useful because it punctures the magical reading of the feature. This is not one giant chat response. It is a visible run: phases, files, agent counts, token counts, and elapsed time. For clinical AI teams, that visibility is the difference between “the model said so” and “we can inspect how the model got there.”
How Thariq Explained It
Two days later, Thariq Shihipar and Sid Bidasaria from Anthropic published a more practical explainer: A harness for every task. Their core idea is simple: Claude Code can now write a custom harness for the task in front of it.
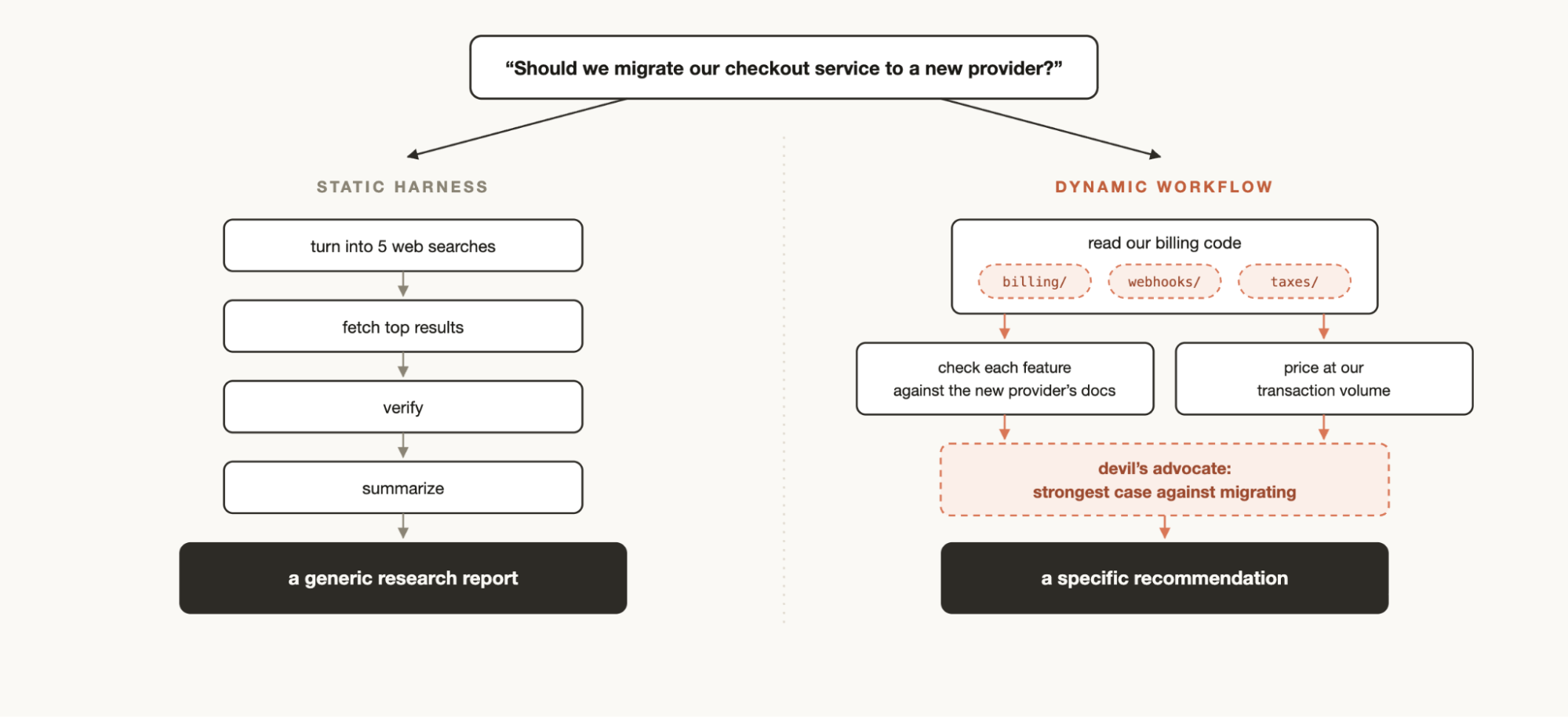
That is the part missing from most superficial coverage. A static workflow is a pre-written recipe. A dynamic workflow is a recipe Claude writes after looking at the goal. If the task is a billing migration, it may inspect billing code, check webhooks, compare tax logic, run a devil’s advocate agent, and return a recommendation. If the task is source verification, it may extract every factual claim, assign claim checkers, audit source quality, and synthesize a verified report.
Thariq and Sid also named the failure modes this is trying to reduce: stopping early on hard work, preferring one’s own previous answer, and drifting away from the original goal as context gets long. Those same failure modes are familiar in clinical AI evaluation. A model can stop after checking the easy part, over-trust its first interpretation, or slowly lose the boundaries set by the clinician.
The Mental Model: Six Patterns
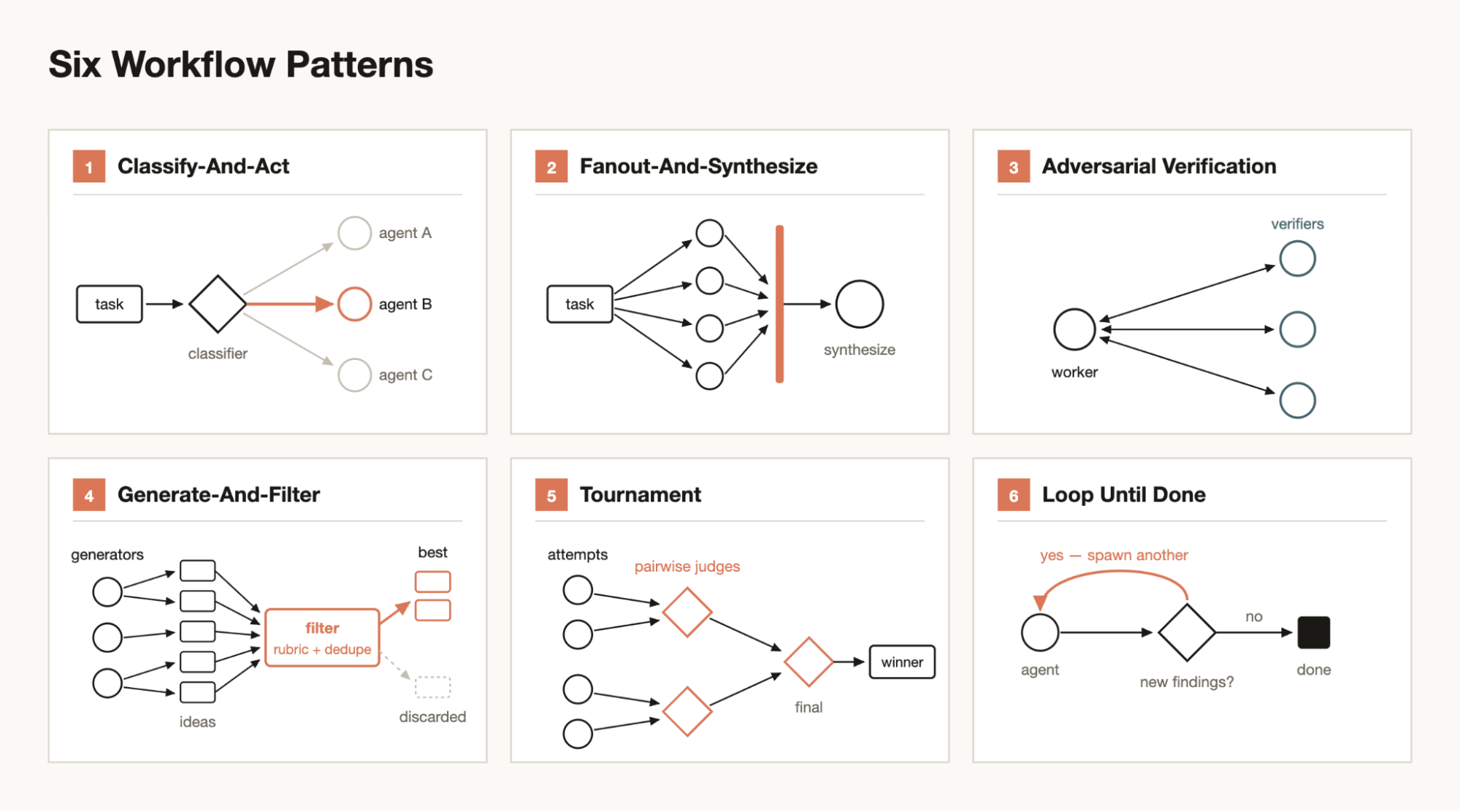
For a physician, the easiest way to read the six patterns is to translate them into clinical review behaviors:
| Workflow pattern | Clinical AI equivalent | What must stay human-led |
|---|---|---|
| Classify-and-act | Route a chart-review task into safety, evidence, privacy, or workflow buckets. | The routing rubric and escalation threshold. |
| Fanout-and-synthesize | Send separate claims to separate source checkers, then combine only verified findings. | Final interpretation and clinical relevance. |
| Adversarial verification | Ask a second agent to disprove the first agent’s conclusion before it reaches the physician. | Whether a disputed point changes care, documentation, or risk. |
| Loop until done | Repeat verification until no new high-risk findings appear, or until a hard stop rule is reached. | The stop rule, budget, and decision to escalate uncertainty. |
A Clinical Safety Map
Here is the safer way to think about the feature in a medical environment. Do not imagine Claude Code running patient care. Imagine a governed review pipeline around a clinical AI artifact: a draft policy, a triage logic document, a model-evaluation memo, or a patient-education article.
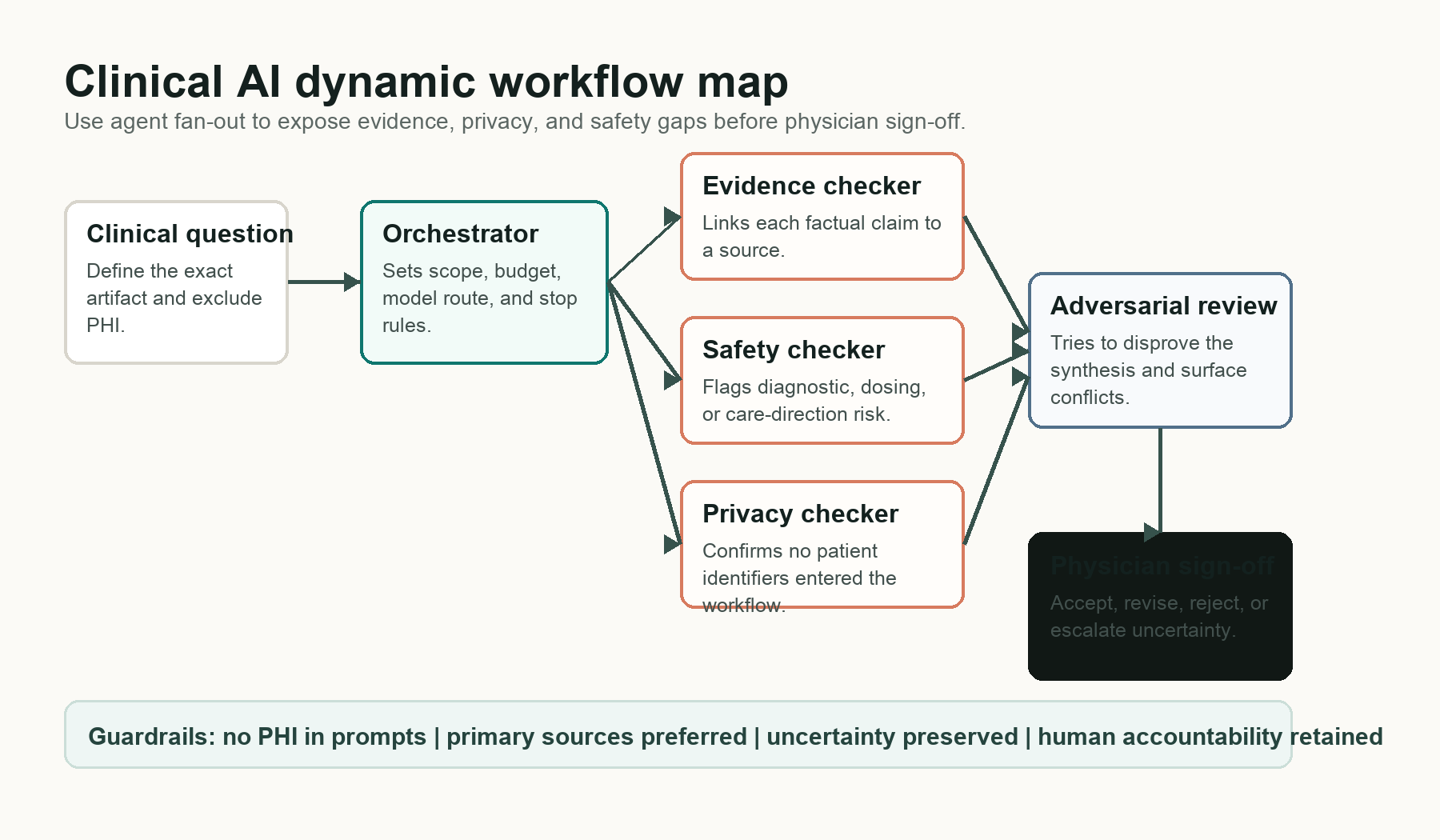
The picture is intentionally boring. It should be. In clinical AI, the interesting part is not how many agents you can spawn. The interesting part is whether each agent has a narrow job, whether the source trail is inspectable, whether privacy is protected, and whether uncertainty survives all the way to the final clinician.
| Boundary | Clinical meaning |
|---|---|
| Good use | Audit a clinical AI article for unsupported claims, missing primary sources, privacy leakage, and unsafe wording before publication. |
| Risky use | Ask a multi-agent workflow to decide what should happen to a patient, especially with private data or incomplete clinical context. |
| Best use | Use the workflow to make uncertainty, conflicts, and missing evidence easier for a physician to see. |
This is the professional boundary: dynamic workflows should strengthen review, not blur responsibility.
Why HTML Artifacts Matter
The old article argued that interactive HTML artifacts are the new standard, but it never showed the reader why. Here is the practical reason: Markdown is good for a summary, but weak for supervising a long workflow. A clinical reviewer needs to see the path, not only the conclusion.
A good review artifact should answer five questions on one screen:
- What was the exact task?
- Which agents ran, and what was each agent responsible for?
- Which claims were verified, disputed, or escalated?
- Which sources were used, and were they primary sources?
- What decision still belongs to the clinician?
That is why the workflow UI matters. The terminal screenshot is not decoration. It is a governance surface.
When Not To Use Dynamic Workflows
Thariq and Sid were careful here: workflows are not needed for every task and can use significantly more tokens. Anthropic’s announcement also warns users to start with scoped tasks because dynamic workflows can consume substantially more usage than a typical Claude Code session.
In a clinical AI team, that warning becomes broader than cost:
- Do not use a workflow when a single reviewer and a source checklist would be clearer.
- Do not use a workflow when the inputs contain protected health information that should not enter the tool.
- Do not use a workflow when nobody owns the final decision.
- Do not use a workflow when the output cannot be audited by a human.
Reader checkpoint: would you trust this workflow?
Before trusting a multi-agent result, ask: Did the workflow preserve the original question? Did each subagent have a narrow role? Did any agent try to disprove the conclusion? Are sources linked? Is the final recommendation separated from the evidence? If the answer to any of these is no, the workflow is not ready for clinical use.
What This Means For Physicians
Claude Code dynamic workflows are an engineering feature, but the lesson travels well into clinical AI. The next generation of AI systems will not feel like one chatbot. It will feel like a small review room: a drafter, a source checker, a skeptic, a privacy reviewer, and a synthesizer.
That can be powerful. It can also be dangerous if the room has no chairperson.
For medicine, the chairperson is still the clinician. The workflow can reduce cognitive load by surfacing contradictions, missing sources, and safety concerns. It cannot carry licensure, accountability, bedside context, or patient preference. The safest clinical use of dynamic workflows is not autonomy. It is better supervision.
Sources
- Anthropic: Introducing dynamic workflows in Claude Code, May 28, 2026.
- Thariq Shihipar and Sid Bidasaria: A harness for every task, June 2, 2026.
- Claude Code Docs: Commands, accessed June 4, 2026.
Medical disclaimer: This content is for educational purposes only. It does not constitute medical advice, diagnosis, or treatment. Always consult a qualified healthcare professional for personal medical decisions.
Licensed physician and clinical AI specialist. Founder and Editor-in-Chief of ZayedMD, a physician-led medical publication covering clinical AI, neurology, metabolic health, and evidence-based patient guidance.

