
If you have ever stared at a massive refactoring task or a 100,000-line codebase migration and thought, “I need ten of me to get this done,” Anthropic just gave you something better. On May 28, 2026, they released Claude Opus 4.8. This is not just another incremental model update. Undoubtedly, it represents a major step toward an agentic workflow that actually works in your daily life.
If you’re wondering why this matters for your daily work, let’s take a look at the standout feature of this release. Anthropic has integrated new agentic orchestration capabilities directly into the terminal with Claude Code. This new tool fundamentally changes the way we build software.
What is the Claude Code Dynamic Workflows reality?
The biggest shift in Claude Opus 4.8 is not just about producing smarter text. Instead, it is about coordination. Inspired by the workflows of engineers such as Boris Cherny, Claude now features a coordination mode called Dynamic Workflows within the Claude Code CLI.
Instead of handling one task at a time, Dynamic Workflows allow Claude to act as a master commander. When faced with a codebase-scale migration, it plans the goal and then spawns dozens, or even hundreds, of parallel sub-agents. You can see the setup of this dynamic environment in the official terminal screenshot below.
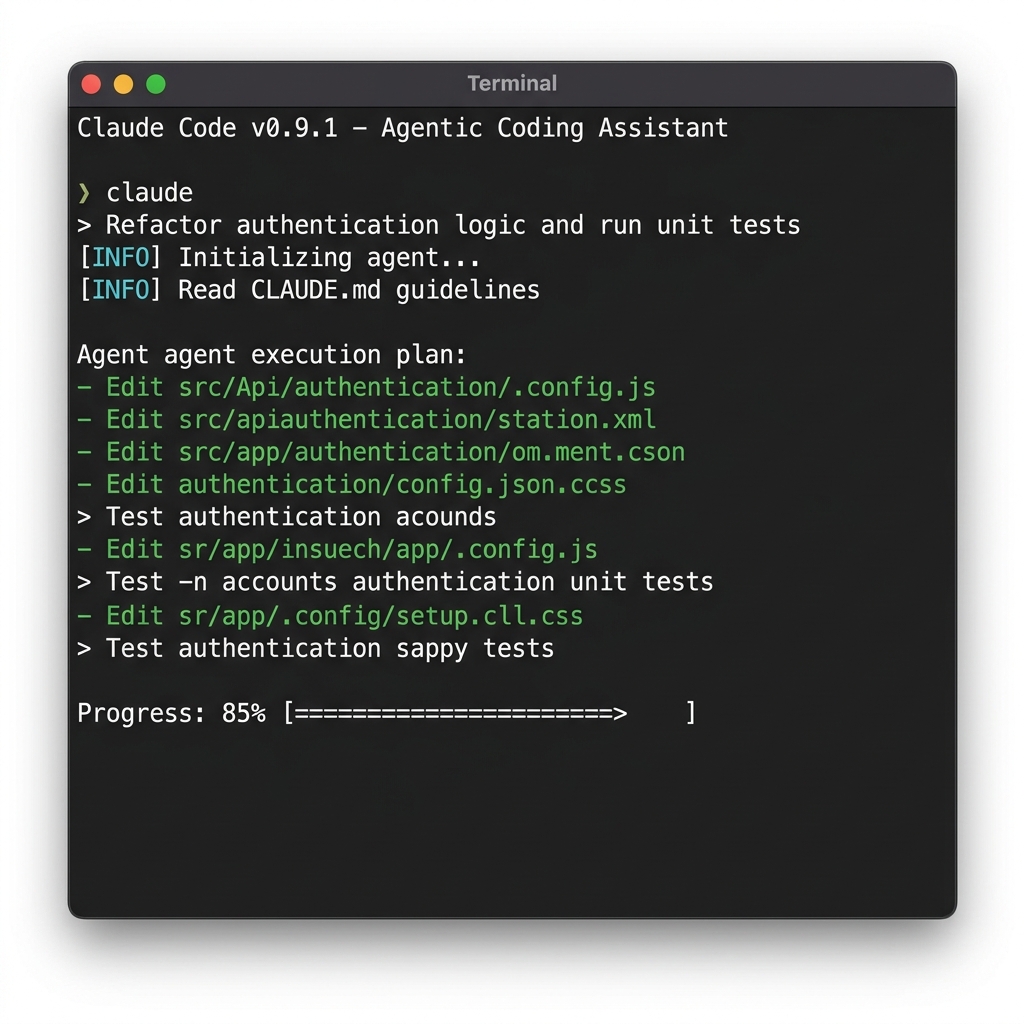
How does adversarial verification work?
This is the essential part of the new system. While some agents implement the code, others act as adversarial verifiers that actively try to find flaws or refute the proposed fixes. They iterate until the solutions converge on a verified result. By using this self-correcting loop, the model ensures that the resulting code actually runs without bugs.
The workflow in practice
You are no longer just coding. In this environment, you are overseeing a fleet of agents. From framework upgrades to security checks, Dynamic Workflows turn weeks of manual work into a single session.
The Claude Code CLI Ecosystem
If you are wondering what makes this tool so useful, the answer lies in how it integrates with your local workspace. Anthropic built several features that allow the agent to learn your specific development rules.
How does project memory work with CLAUDE.md?
The first essential file is CLAUDE.md. When you initialize your project using the /init command, Claude Code creates this file to store your style guides, test commands, and coding rules. The agent reads this file at the start of every session. Because the rules are injected automatically, you can rest assured that the model will follow your formatting standards without you reminding it.
Reusable skills and automated hooks
What’s more, you can create custom skills for the agent. By writing a simple markdown guide inside your project, you define a skill that the agent can use whenever a task matches the description. Beside this, the tool supports automated hooks. You can set up hooks to run specific commands, such as executing tests or linting the codebase, immediately after the agent finishes writing code. This ensures that the agent checks its work before you review it.
Parallel branches with worktrees
Another helpful addition is support for git worktrees. This allows you to run multiple independent Claude Code sessions on separate branches at the same time. While you work on a feature, the agent can debug a separate issue on another branch without messing up your active files.
Helpful shortcuts for managing your agents
Besides this, the CLI tool includes some helpful commands that make coordination easier. For instance, the /btw command stands for “by the way” and lets you type a side query or give secondary commands while the main agent is still running. In that case, you do not have to wait for a long refactoring task to complete just to ask a quick question. You can also type /workflows to check the status of all active sub-agents, pause tasks, or see which files they are working on.
How do effort controls and fast mode help?
One of the most practical additions in this release is the new Effort parameter. Now, you can tell Claude exactly how hard to try. You can adjust this setting using the /effort command.
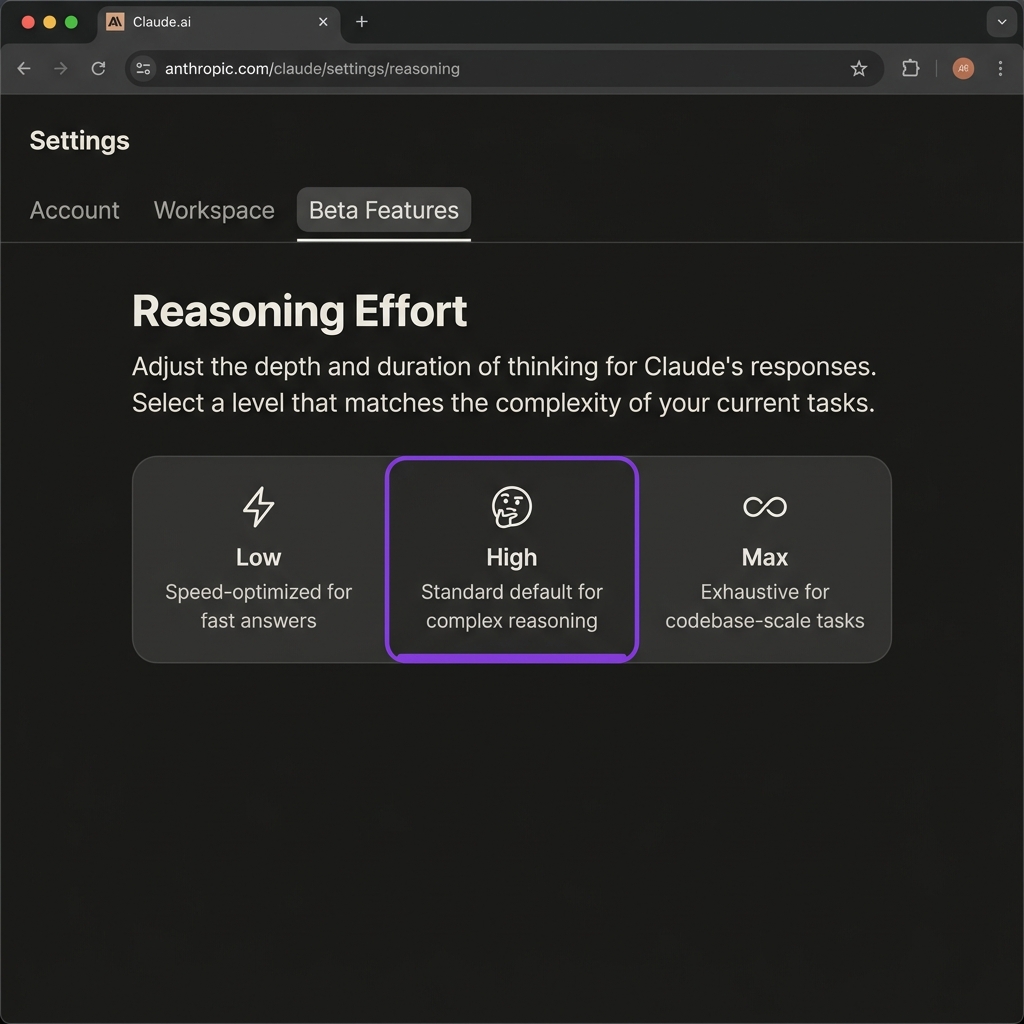
Selecting your thinking level
The low option is speed-optimized and works well for simple lookups or basic boilerplate code. The high option is the default setting and serves as the sweet spot for standard coding tasks. Finally, the max option is reserved for exhaustive reasoning on complex, long-horizon tasks. Yes, you read that right. The model scales its internal thinking based on what you choose.
Cheaper and faster API calls
Moreover, Anthropic introduced a new Fast Mode for the API. This mode runs at two and a half times the speed of the standard model. What’s more, it is three times cheaper, making it an all-rounded solution for high-volume agentic pipelines.
Mid-conversation system messages
For developers building custom software, the latest API update introduces a useful change to the Messages API. You can now pass system instructions directly inside the messages array mid-conversation.
Keeping prompt cache hits high
In previous versions, changing your system prompt meant you had to restart the session. This was expensive because it broke your prompt caching. With this update, you can change instructions on the fly. You can rest assured that your cache hits will remain high, which reduces API latency and saves on costs.
What do the benchmark numbers show?
The test results show that Claude Opus 4.8 is a top performer. On the SWE-bench Pro test, the model scored 69.2 percent. This beats the competitor score of 58.6 percent. Besides this, it scored 84 percent on the Online-Mind2Web benchmark, which tests browser-use and computer-agent tasks.
A major drop in code hallucinations
However, the reliability numbers are what caught my eye. The model is four times less likely to ignore code flaws than the older version. In the coding world, a model that tells you it is not sure is much more valuable than one that confidently writes a bug, right? It also completed every task on the internal Legal Agent Benchmark and the Super-Agent benchmark, showing that it can handle long-horizon work.
Understanding the honesty score
What’s more, the improvements in honesty are essential for professional use. When a model misses a syntax error, it wastes hours of developer time. Claude Opus 4.8 addresses this by scaling its confidence checks. If you ask the model to review a script, it will actively raise doubts if the code looks questionable rather than greenlighting a broken patch.
The future of security with Claude Mythos
Anthropic also shared a preview of a research-grade model class called Claude Mythos. Currently, this model is limited to partners under Project Glasswing for cybersecurity safeguards.
Spotting complex security flaws
It is designed to identify vulnerabilities at a level that goes beyond human security experts. If you follow these safeguards, security on large networks will be much easier to manage. It represents a new horizon for safety in AI.
Conclusion
Undoubtedly, this update is a major advance for autonomous software development. By providing a terminal tool that coordinates parallel sub-agents and verifying its own output, Anthropic has changed what we expect from AI code assistants. It makes managing massive codebase changes a much simpler task, right?
Licensed physician and clinical AI specialist. Founder and Editor-in-Chief of ZayedMD, a physician-led medical publication covering clinical AI, neurology, metabolic health, and evidence-based patient guidance.


